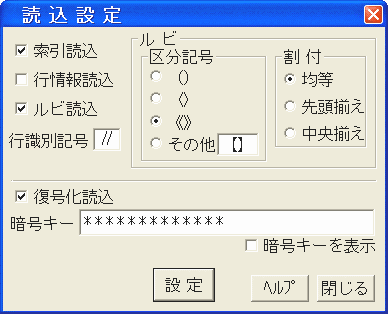
○ 読込設定
読込み時、文書(テキスト)ファイル中にある構成索引、行の書式、ルビの各データを本エディタの内部データに変換処理します。ここではその際に必要な情報の設定をします。
この読込変換処理は「名前を付けて保存」の「書出設定」の逆処理です。
この画像の各部分をクリックすると該当項目の説明に飛びます。
□索引読込
このボックスをチェックするとテキストファイルからの構成索引変換処理を実行し、保存時には拡張ファイルに保存され、テキスト本体からは行情報の格納行が削除されます。
チェックしなければ構成索引の変換はせず、テキスト内にそのまま読込まれ、保存時にもそのまま残ります。
□行情報読込
このボックスをチェックするとテキストファイルからの行の情報(行の書式とマークジャンプ)変換処理を実行し、保存時には拡張ファイルに保存され、テキスト本体からは行情報の格納行が削除されます。
チェックしなければ行の情報(行の書式とマークジャンプ)の変換はせず、テキスト内にそのまま読込まれ、保存時にもそのまま残ります。
□ルビ読込
このボックスをチェックするとテキストファイルからのルビ変換処理を実行し、保存時には拡張ファイルに保存され、テキスト本体からはルビ部分が削除されます。
チェックしなければルビの変換はせず、テキスト内にそのまま読込まれ、保存時にもそのまま残ります。
●行識別記号
構成索引データと行の情報(行の書式とマークジャンプ)を格納してある行の先頭記号を指定します。
これは2バイト(半角2文字あるいは全角1文字)で指定します。
文書ファイル中にある行情報データを確認して指定してください。
●ルビ区分記号
ルビ(フリガナ)の前後に付いている区分記号を指定します。
文書ファイル中にあるルビデータを確認して指定してください。
「()・〈〉・《》」は選択で指定出来ます。これ以外の区分記号は「その他」の欄に必ず2文字一組で入力してください。
●割 付
ルビを対象文字列に対してどのように割付するかを指定します。
均 等 : 対象文字列の長さに応じてルビ文字を均等に割付します。
先頭揃え : 対象文字列の先頭からルビ文字を詰めて割付します。
中央揃え : 対象文字列の中央にルビ文字を詰めて割付します。
※編集中のルビ振りにおいては割付を個々のルビ毎に選べますが、この処理では全て同一の割付形式となります。
□復号化読込
暗号化されている文書ファイルを読込む場合、このボックスをチェックします。
同時に、暗号化した時に設定した暗号キーを入力します。暗号キーは全角も使えます。
詳しくは文書の暗号化保存とファイルの暗号/復号化を参照してください。